Store embeddings in chroma with persistent storage (nodejs and python examples)

Chroma is an open-source vector database designed for AI applications that need to store, query, and manage embeddings efficiently. This tutorial demonstrates how to deploy Chroma with persistent storage on Upsun, along with both Python and Node.js client applications that can ingest documents and store their embeddings.
Why Chroma?
Chroma excels in several use cases:
- Semantic Search: Find documents based on meaning rather than exact keyword matches
- Retrieval Augmented Generation (RAG): Enhance LLMs with relevant context from your knowledge base
- Recommendation Systems: Build similarity-based recommendation engines
- Content Classification: Automatically categorize documents based on their semantic content
- Duplicate Detection: Identify similar or duplicate content across large document collections
Architecture Overview
graph LR
subgraph "Upsun Platform"
subgraph "Applications"
PY[Python App
Flask + uv]
NODE[Node.js App
Express + TypeScript]
CHROMA[Chroma Server
Vector Database]
end
subgraph "Storage"
STORAGE[(Persistent Storage
.db & .chroma)]
end
subgraph "External Services"
OPENAI[OpenAI API
Embeddings]
end
end
subgraph "Routes"
PYROUTE[python.domain.com]
NODEROUTE[nodejs.domain.com]
end
%% Connections
PY -.->|HTTP| CHROMA
NODE -.->|HTTP| CHROMA
CHROMA --> STORAGE
PY -->|API calls| OPENAI
NODE -->|API calls| OPENAI
PYROUTE --> PY
NODEROUTE --> NODE
%% Styling with Upsun colors
classDef primary fill:#D0F302,stroke:#000,stroke-width:2px,color:#000
classDef secondary fill:#6046FF,stroke:#000,stroke-width:2px,color:#fff
classDef storage fill:#fff,stroke:#000,stroke-width:2px,color:#000
classDef external fill:#f9f9f9,stroke:#000,stroke-width:1px,color:#000
class PY,NODE,CHROMA primary
class PYROUTE,NODEROUTE secondary
class STORAGE,OPENAI storageOur setup includes three applications:
- Chroma Server: The vector database with persistent storage
- Python Application: Uses uv for dependency management and Flask for the web interface
- Node.js Application: TypeScript-based Express server
Both client applications can ingest markdown documents, generate embeddings using OpenAI’s API, and store them in Chroma.
Chroma configuration on Upsun
The .upsun/config.yaml file defines our multi-applications setup. Let’s start with the Chroma server configuration:
applications:
chroma:
type: "python:3.12"
source:
root: "chroma"
dependencies:
python3:
uv: "*"
hooks:
build: |
uv init
uv add chromadb
web:
commands:
start: "uv run --no-sync chroma run --host 0.0.0.0 --port $PORT --path /app/.db"
mounts:
".db":
source: "storage"
source_path: "db"
".chroma":
source: "storage"
source_path: "chroma"
variables:
env:
uv_CACHE_DIR: "/tmp/uv-cache"
PYTHONPATH: "."Key configuration points for Chroma:
- Persistent Storage: Chroma uses mounted volumes to persist data between deployments
- uv Integration: Uses uv for fast, reliable dependency management
- Internal Access: Other applications connect via internal networking
Note that Chroma doesn’t have a public HTTP endpoint, it’s only accessible internally within the Upsun platform. The Python and Node.js applications will establish relationships to Chroma through their respective configurations, allowing them to connect to the vector database using the internal chroma.internal hostname.
Python implementation
The Python application uses uv for dependency management and includes both ingestion and web interface capabilities.
Upsun configuration
python-app:
source:
root: "python-app"
type: "python:3.12"
dependencies:
python3:
uv: "*"
hooks:
build: |
uv sync --frozen
deploy: |
uv run --no-sync python ingest.py
web:
commands:
start: "uv run --no-sync uvicorn main:main --reload --host 0.0.0.0 --port $PORT"
relationships:
chroma: chroma:http
variables:
env:
uv_CACHE_DIR: "/tmp/uv-cache"
PYTHONPATH: "."The Python app route configuration:
routes:
"https://python.{default}/":
type: upstream
upstream: "python-app:http"Document ingestion
The ingestion script processes markdown files and stores their embeddings:
import os
import glob
import chromadb
from openai import OpenAI
from typing import List, Dict
import hashlib
def read_markdown_files(data_dir: str = "data") -> List[Dict[str, str]]:
"""Read all markdown files from the data directory."""
md_files = glob.glob(os.path.join(data_dir, "*.md"))
documents = []
for file_path in md_files:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
documents.append({
"content": content,
"filename": os.path.basename(file_path),
"filepath": file_path
})
return documents
def chunk_text(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[str]:
"""Split text into overlapping chunks."""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = " ".join(words[i:i + chunk_size])
if chunk.strip():
chunks.append(chunk)
return chunks
def get_chroma_client():
"""Create Chroma client based on environment variables."""
chroma_host = os.getenv("CHROMA_HOST")
chroma_port = os.getenv("CHROMA_PORT", "8000")
chroma_ssl = os.getenv("CHROMA_SSL", "false").lower() == "true"
chroma_headers = {}
if os.getenv("CHROMA_AUTH_TOKEN"):
chroma_headers["Authorization"] = f"Bearer {os.getenv('CHROMA_AUTH_TOKEN')}"
if chroma_host:
return chromadb.HttpClient(
host=chroma_host,
port=int(chroma_port),
ssl=chroma_ssl,
headers=chroma_headers
)
else:
return chromadb.Client()
def ingest_documents(data_dir: str = "data", collection_name: str = "python-app"):
"""Main ingestion function."""
openai_client = OpenAI()
chroma_client = get_chroma_client()
# Get or create collection
try:
collection = chroma_client.get_collection(name=collection_name)
collection.delete()
except Exception:
collection = chroma_client.create_collection(name=collection_name)
# Process documents
documents = read_markdown_files(data_dir)
all_chunks = []
all_metadatas = []
all_ids = []
for doc in documents:
chunks = chunk_text(doc['content'])
for i, chunk in enumerate(chunks):
all_chunks.append(chunk)
all_metadatas.append({
"filename": doc['filename'],
"filepath": doc['filepath'],
"chunk_index": i,
"total_chunks": len(chunks)
})
content_hash = hashlib.md5(chunk.encode()).hexdigest()[:8]
all_ids.append(f"{doc['filename']}_{i}_{content_hash}")
# Generate embeddings and store
batch_size = 100
all_embeddings = []
for i in range(0, len(all_chunks), batch_size):
batch_chunks = all_chunks[i:i + batch_size]
response = openai_client.embeddings.create(
model="text-embedding-3-small",
input=batch_chunks
)
batch_embeddings = [embedding.embedding for embedding in response.data]
all_embeddings.extend(batch_embeddings)
collection.add(
documents=all_chunks,
metadatas=all_metadatas,
ids=all_ids,
embeddings=all_embeddings
)
print(f"Successfully ingested {len(all_chunks)} chunks")Flask web interface
The main application provides a web interface to view stored documents:
import os
import chromadb
from flask import Flask, render_template_string
from collections import defaultdict
app = Flask(__name__)
def get_chroma_client():
"""Create Chroma client based on environment variables."""
chroma_host = os.getenv("CHROMA_HOST")
chroma_port = os.getenv("CHROMA_PORT", "8000")
chroma_ssl = os.getenv("CHROMA_SSL", "false").lower() == "true"
chroma_headers = {}
if os.getenv("CHROMA_AUTH_TOKEN"):
chroma_headers["Authorization"] = f"Bearer {os.getenv('CHROMA_AUTH_TOKEN')}"
if chroma_host:
return chromadb.HttpClient(
host=chroma_host,
port=int(chroma_port),
ssl=chroma_ssl,
headers=chroma_headers
)
else:
return chromadb.Client()
@app.route('/')
def list_files():
try:
chroma_client = get_chroma_client()
collection = chroma_client.get_collection(name="python-app")
result = collection.get()
metadatas = result['metadatas']
if not metadatas:
return render_template_string(HTML_TEMPLATE,
error="No documents found. Run ingest.py first.")
# Group chunks by filename
file_chunks = defaultdict(int)
for metadata in metadatas:
filename = metadata.get('filename', 'Unknown')
file_chunks[filename] += 1
files = []
for filename, chunk_count in sorted(file_chunks.items()):
files.append({
'filename': filename,
'chunk_count': chunk_count
})
return render_template_string(HTML_TEMPLATE,
files=files,
total_files=len(files),
total_chunks=sum(file_chunks.values()))
except Exception as e:
return render_template_string(HTML_TEMPLATE,
error=f"Error: {str(e)}")Node.js implementation
The Node.js application uses TypeScript and Express, with similar document ingestion capabilities.
Upsun configuration
nodejs-app:
source:
root: "nodejs-app"
type: nodejs:22
web:
commands:
start: "npm run start"
hooks:
build: |
npm ci
npm run build
deploy: |
npm run ingest
relationships:
chroma: chroma:httpThe Node.js app route configuration:
routes:
"https://nodejs.{default}/":
type: upstream
upstream: "nodejs-app:http"TypeScript ingestion script
import { ChromaClient, OpenAIEmbeddingFunction } from 'chromadb';
import OpenAI from 'openai';
import { readFileSync } from 'fs';
import { glob } from 'glob';
import path from 'path';
import { createHash } from 'crypto';
function getChromaClient(): ChromaClient {
const chromaHost = process.env.CHROMA_HOST;
const chromaPort = parseInt(process.env.CHROMA_PORT || '8000');
const chromaSsl = process.env.CHROMA_SSL?.toLowerCase() === 'true';
if (chromaHost) {
const auth = process.env.CHROMA_AUTH_TOKEN
? { provider: 'token', credentials: process.env.CHROMA_AUTH_TOKEN }
: undefined;
return new ChromaClient({
path: `http${chromaSsl ? 's' : ''}://${chromaHost}:${chromaPort}`,
auth
});
} else {
return new ChromaClient();
}
}
export async function ingestDocuments(dataDir: string = 'data', collectionName: string = 'nodejs-app'): Promise<void> {
const openaiClient = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
});
const chromaClient = getChromaClient();
const embedder = new OpenAIEmbeddingFunction({
openai_api_key: process.env.OPENAI_API_KEY!,
openai_model: 'text-embedding-3-small'
});
// Get or create collection
let collection;
try {
collection = await chromaClient.getCollection({
name: collectionName,
embeddingFunction: embedder
});
await collection.delete();
} catch (error) {
collection = await chromaClient.createCollection({
name: collectionName,
embeddingFunction: embedder
});
}
// Read and process documents
const mdFiles = glob.sync(path.join(dataDir, '*.md'));
const allChunks: string[] = [];
const allMetadatas: any[] = [];
const allIds: string[] = [];
for (const filePath of mdFiles) {
const content = readFileSync(filePath, 'utf-8');
const chunks = chunkText(content);
for (let i = 0; i < chunks.length; i++) {
const chunk = chunks[i];
allChunks.push(chunk);
allMetadatas.push({
filename: path.basename(filePath),
filepath: filePath,
chunk_index: i,
total_chunks: chunks.length
});
const contentHash = createHash('md5').update(chunk).digest('hex').substring(0, 8);
allIds.push(`${path.basename(filePath)}_${i}_${contentHash}`);
}
}
// Store in Chroma
await collection.add({
documents: allChunks,
metadatas: allMetadatas,
ids: allIds
});
console.log(`Successfully ingested ${allChunks.length} chunks`);
}Express web server
import express from 'express';
import { ChromaClient, OpenAIEmbeddingFunction } from 'chromadb';
const app = express();
function getChromaClient(): ChromaClient {
const chromaHost = process.env.CHROMA_HOST;
const chromaPort = parseInt(process.env.CHROMA_PORT || '8000');
const chromaSsl = process.env.CHROMA_SSL?.toLowerCase() === 'true';
if (chromaHost) {
const auth = process.env.CHROMA_AUTH_TOKEN
? { provider: 'token', credentials: process.env.CHROMA_AUTH_TOKEN }
: undefined;
return new ChromaClient({
path: `http${chromaSsl ? 's' : ''}://${chromaHost}:${chromaPort}`,
auth
});
} else {
return new ChromaClient();
}
}
app.get('/', async (req, res) => {
try {
const chromaClient = getChromaClient();
const embedder = new OpenAIEmbeddingFunction({
openai_api_key: process.env.OPENAI_API_KEY!,
openai_model: 'text-embedding-3-small'
});
const collection = await chromaClient.getCollection({
name: 'nodejs-app',
embeddingFunction: embedder
});
const result = await collection.get();
const metadatas = result.metadatas;
if (!metadatas || metadatas.length === 0) {
const errorContent = `<div class="error">No documents found. Run npm run ingest first.</div>`;
return res.send(HTML_TEMPLATE.replace('{{CONTENT}}', errorContent));
}
// Group and display file statistics
const fileChunks = new Map();
for (const metadata of metadatas) {
const filename = metadata?.filename || 'Unknown';
fileChunks.set(filename, (fileChunks.get(filename) || 0) + 1);
}
// Generate HTML content
let content = `<div class="total"><strong>Total Files:</strong> ${fileChunks.size}<br><strong>Total Chunks:</strong> ${metadatas.length}</div>`;
for (const [filename, chunkCount] of Array.from(fileChunks.entries()).sort()) {
content += `<div class="file-item"><div class="file-name">📄 ${filename}</div><div class="chunk-count">${chunkCount} chunks</div></div>`;
}
res.send(HTML_TEMPLATE.replace('{{CONTENT}}', content));
} catch (error) {
const errorContent = `<div class="error">Error: ${error.message}</div>`;
res.send(HTML_TEMPLATE.replace('{{CONTENT}}', errorContent));
}
});Deployment
To deploy this setup:
Clone the repository:
Terminalgit clone https://github.com/upsun/tutorial-chromadb.git cd tutorial-chromadbCreate a new Upsun project:
Terminalupsun createSet up the OpenAI environment variable:
Terminalupsun variable:create -e main --level project --name OPENAI_API_KEY --value "your-openai-key"Deploy to Upsun:
Terminalupsun deploy
The deployment process will:
- Set up the Chroma server with persistent storage
- Build and deploy both Python and Node.js applications
- Automatically run document ingestion during deployment
- Configure internal networking between applications
The deploy hook injests the data for both apps:
Executing deploy hook for application nodejs-app
> nodejs-app@0.1.0 ingest
> node dist/ingest.js
Created new collection: nodejs-app
Found 13 markdown files
Processing: why-python-developers-should-switch-to-uv.md
Created 2 chunks
[...]
Total chunks to process: 36
Storing in ChromaDB...
Successfully ingested 36 chunks into collection 'nodejs-app'You can now access your deployed applications with the endpoint displayed in the CLI or the console.
Python app:
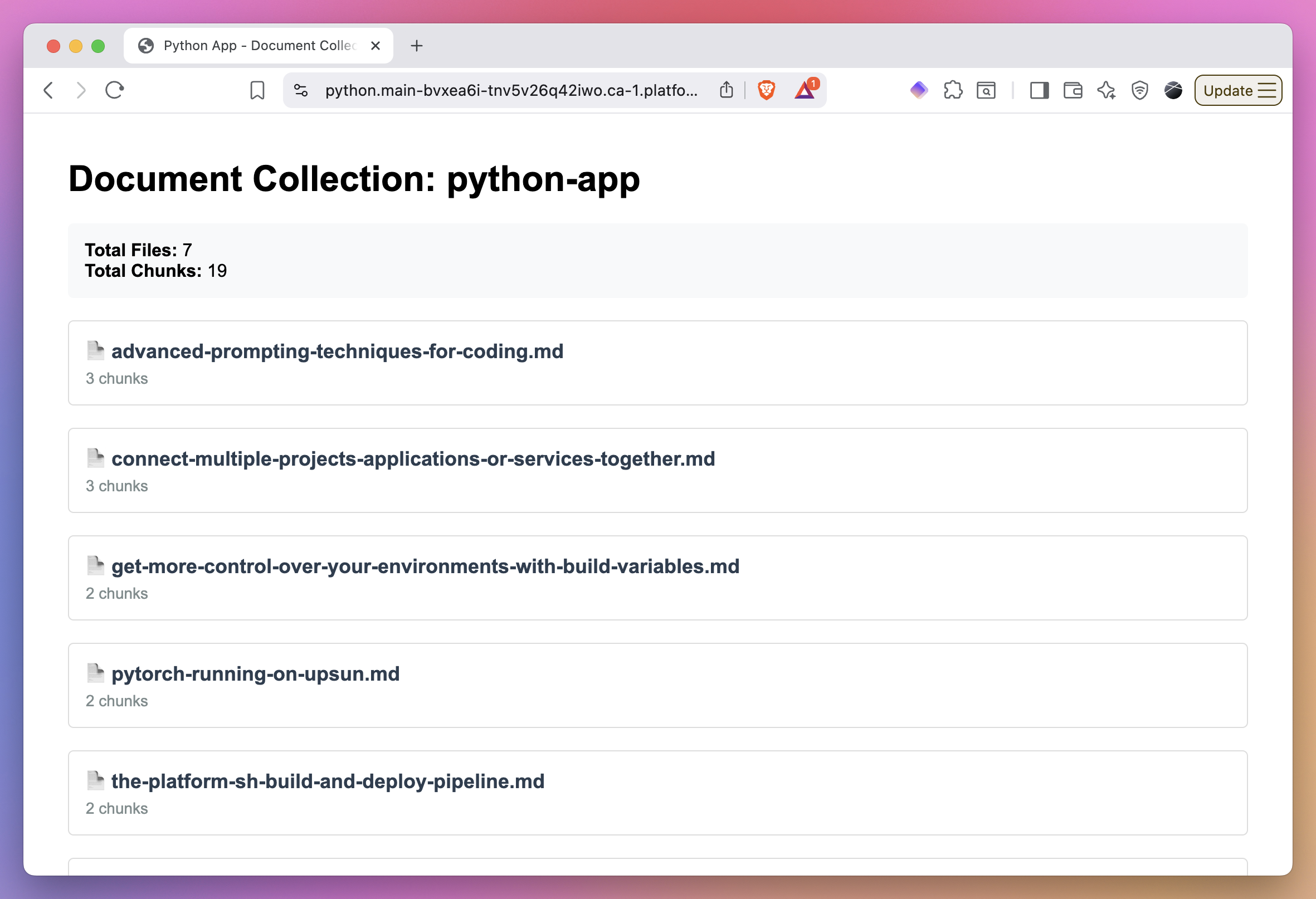
Node.js app:
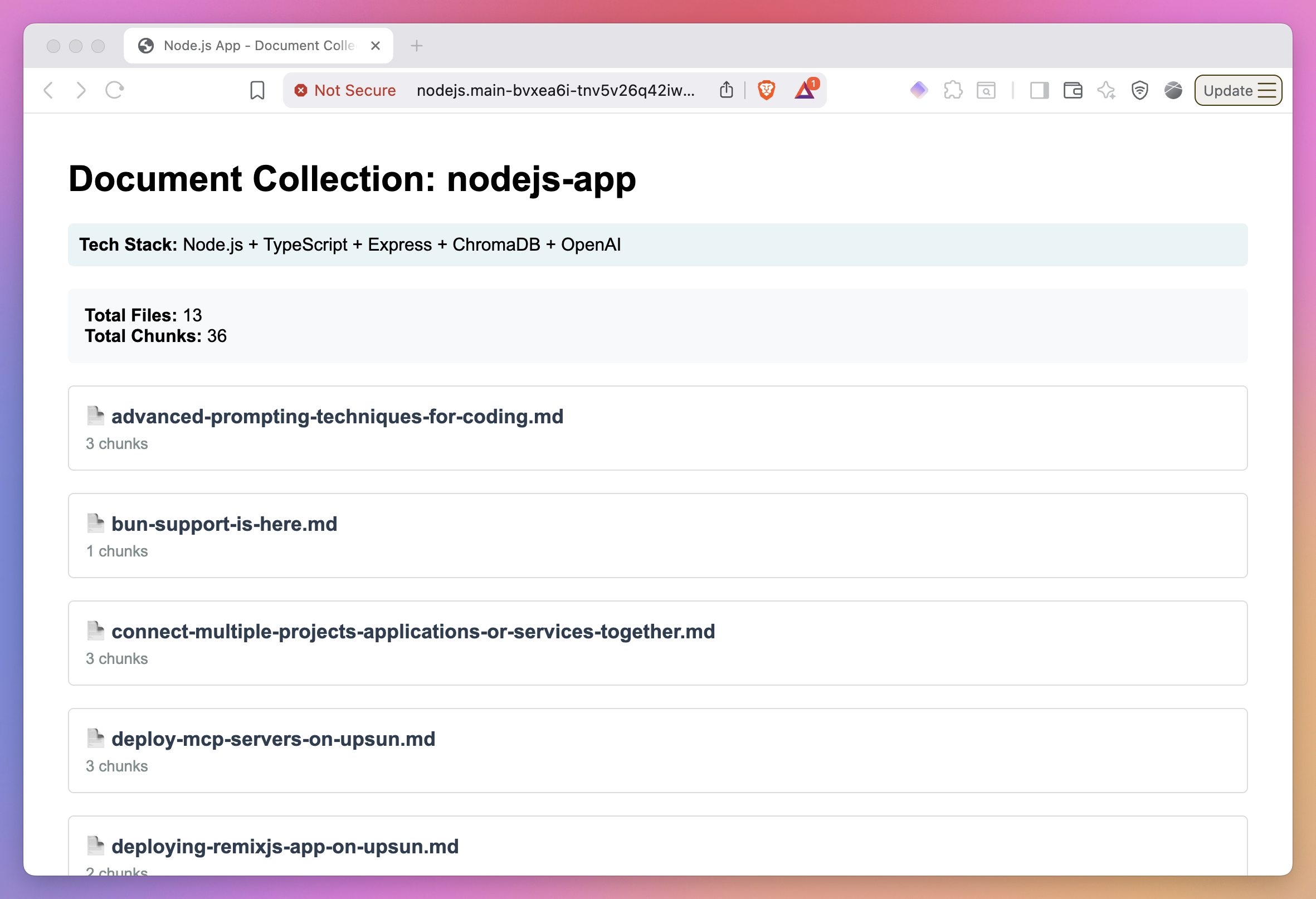
Both applications will display the ingested documents and their chunk counts, demonstrating successful embedding storage in Chroma with persistent storage across deployments.