Experiment with Chainlit AI interface with RAG on Upsun

What is Chainlit?
Chainlit is an open-source async Python framework which allows developers to build scalable Conversational AI or agentic applications. While providing the base framework, Chainlit gives you full flexibility to implement any external API, logic or local models you want to run.
In this tutorial we will be implementing RAG (Retrieval Augmented Generation) in two ways:
- The first will leverage OpenAI assistants with uploaded documents
- The second will be using
llama_indexwith a local folder of documents
Setting up Chainlit locally
Virtualenv
Let’s start by creating our virtualenv:
mkdir chainlit && cd chainlit
python3 -m venv venv
source venv/bin/activateInstall dependencies
We are now adding our dependencies and freeze them:
pip install chainlit
pip install llama_index # Useful only for case #2
pip install openai
pip freeze > requirements.txtTest Chainlit
Let’s start chainlit:
chainlit helloYou should now see a placeholder on http://localhost:8000/
Let’s deploy it on Upsun
Init the git repository
git init .Don’t forget to add a .gitignore file. Some folders will be used later on.
.env
database/**
data/**
storage/**
.chainlit
venv
__pycache__Create an Upsun project
upsun project:create # follow the promptsThe Upsun CLI will automatically set the upsun remote on your local git repository.
Let’s add the configuration
Here is an example configuration to run Chainlit:
applications:
chainlit:
source:
root: "/"
type: "python:3.11"
mounts:
"/database":
source: "storage"
source_path: "database"
".files":
source: "storage"
source_path: "files"
"__pycache__":
source: "storage"
source_path: "pycache"
".chainlit":
source: "storage"
source_path: ".chainlit"
web:
commands:
start: "chainlit run app.py --port $PORT --host 0.0.0.0"
upstream:
socket_family: tcp
locations:
"/":
root: ""
passthru: true
"/public":
passthru: true
build:
flavor: none
hooks:
build: |
set -eux
pip install -r requirements.txt
deploy: |
set -eux
# post_deploy: |
routes:
"https://{default}/":
type: upstream
upstream: "chainlit:http"
"https://www.{default}":
type: redirect
to: "https://{default}/"Nothing out of the ordinary there! We install all dependencies in the build hook and then start the app with chainlit directly and we specify the port it should run on.
OPENAI_API_KEY to either the configuration or your environment variables on the Upsun console or through the CLI. You can get the key by generating it on the OpenAI Platform site.To add it as an environment variable through the CLI, you can use:
upsun variable:create env:OPENAI_API_KEY --value=sk-proj[...]Let’s deploy!
Commit the files and configuration to deploy!
git add .
git commit -m "First chainlit example"
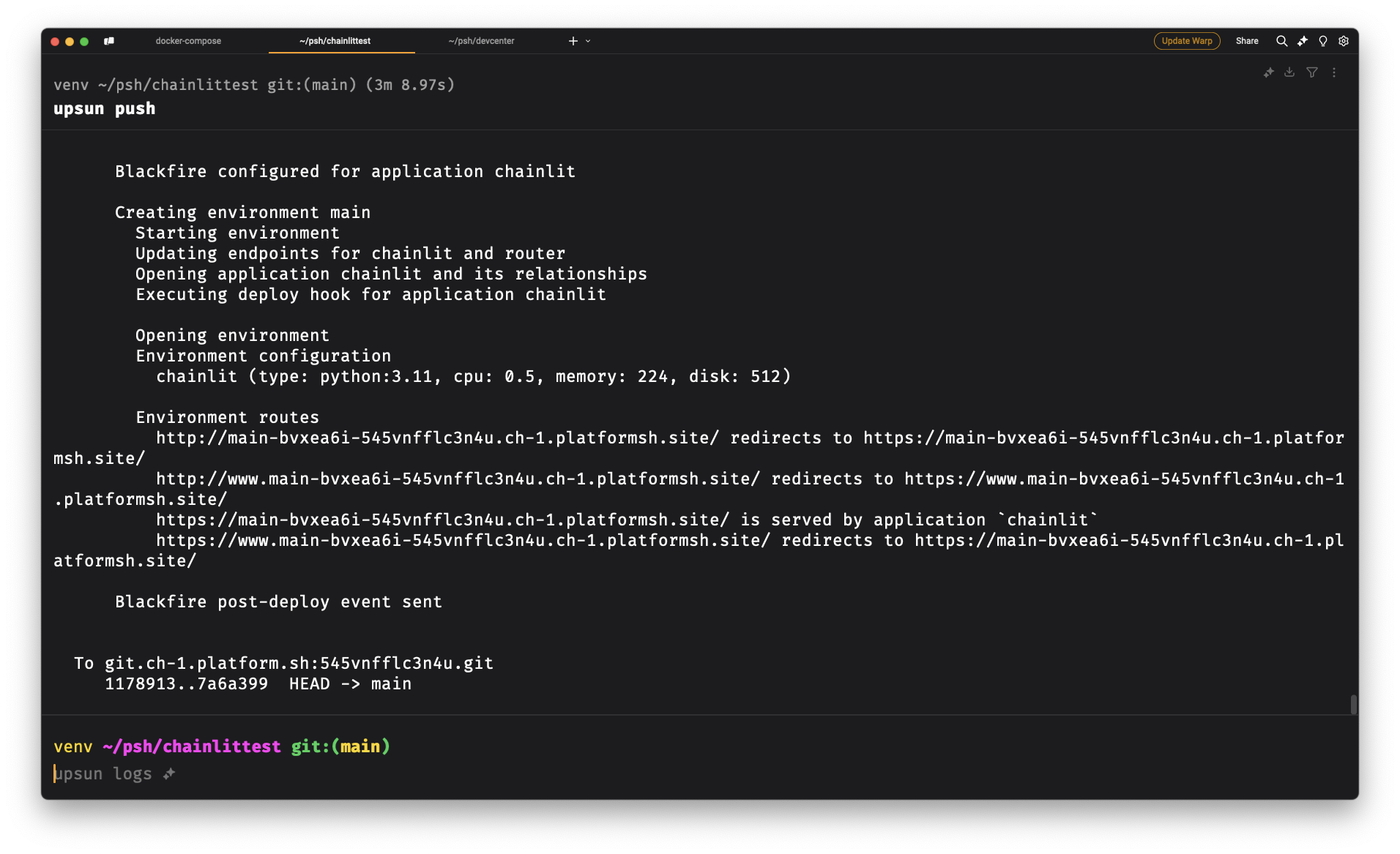
upsun pushReview the deployment
If everything goes well, you should have Chainlit deployed and working correctly on your main environment:
First implementation: OpenAI Assistant & uploaded files
The goal here is to make Chainlit work with an OpenAI assistant. Our content will be loaded directly in the assistant on OpenAI.
Create the assistant
Go to the Platform Assistants page and create a new one.
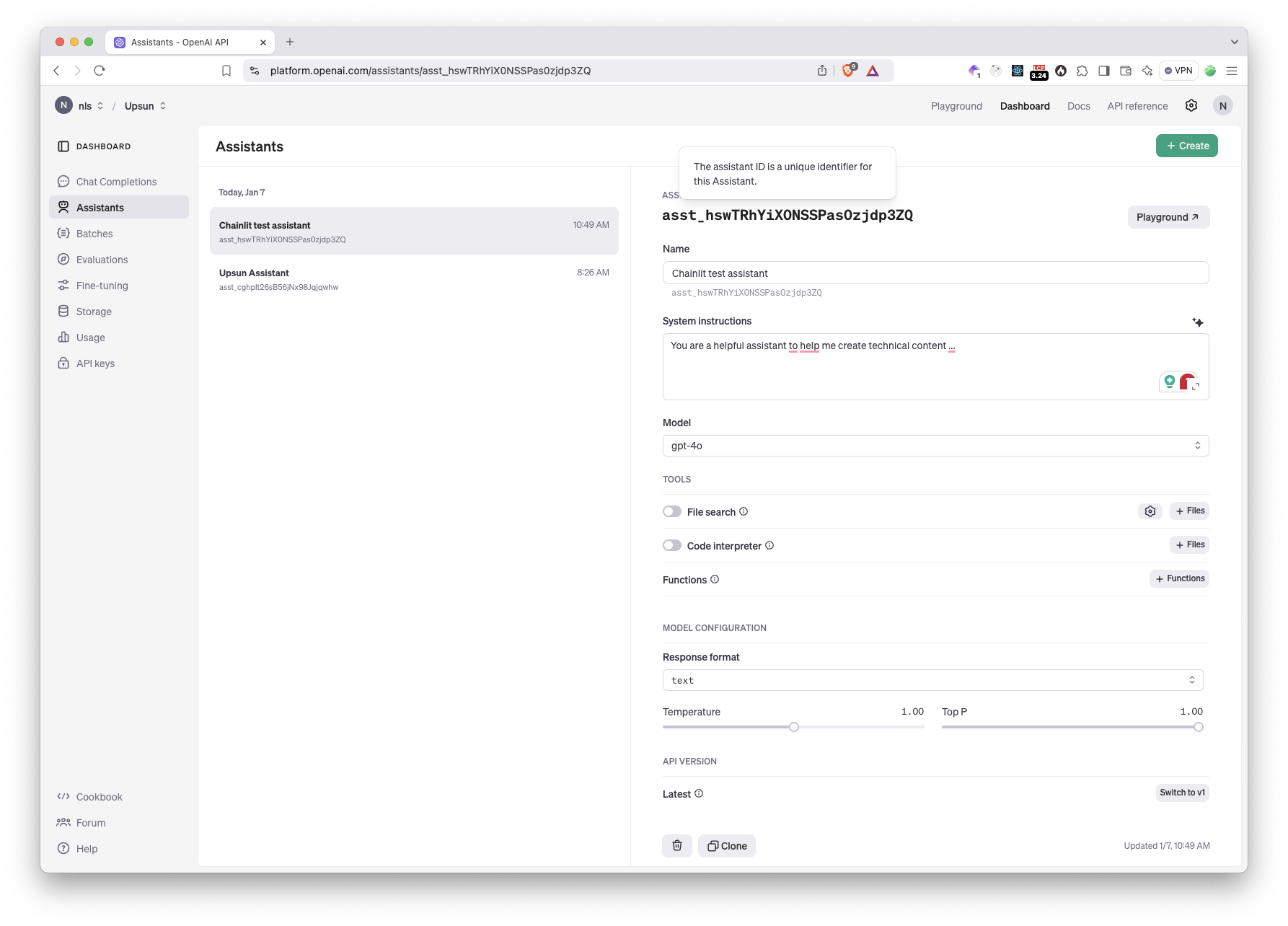
Set the system instructions and select the model you want to use. Make sure the Response Format is set to text. I like to keep the temperature low, around 0.10 to avoid hallucinations.
Copy your assistant ID asst_[xxx] and add it to your environment variables:
upsun variable:create env:OPENAI_ASSISTANT_ID --value=asst_[...]Upload your content
Enable the File search toggle and click + Files. Upload your content. While OpenAI is capable of ingesting a lot of different file formats, I like to upload only Markdown as it is faster and easier to parse, removing potential issues with PDF for example.
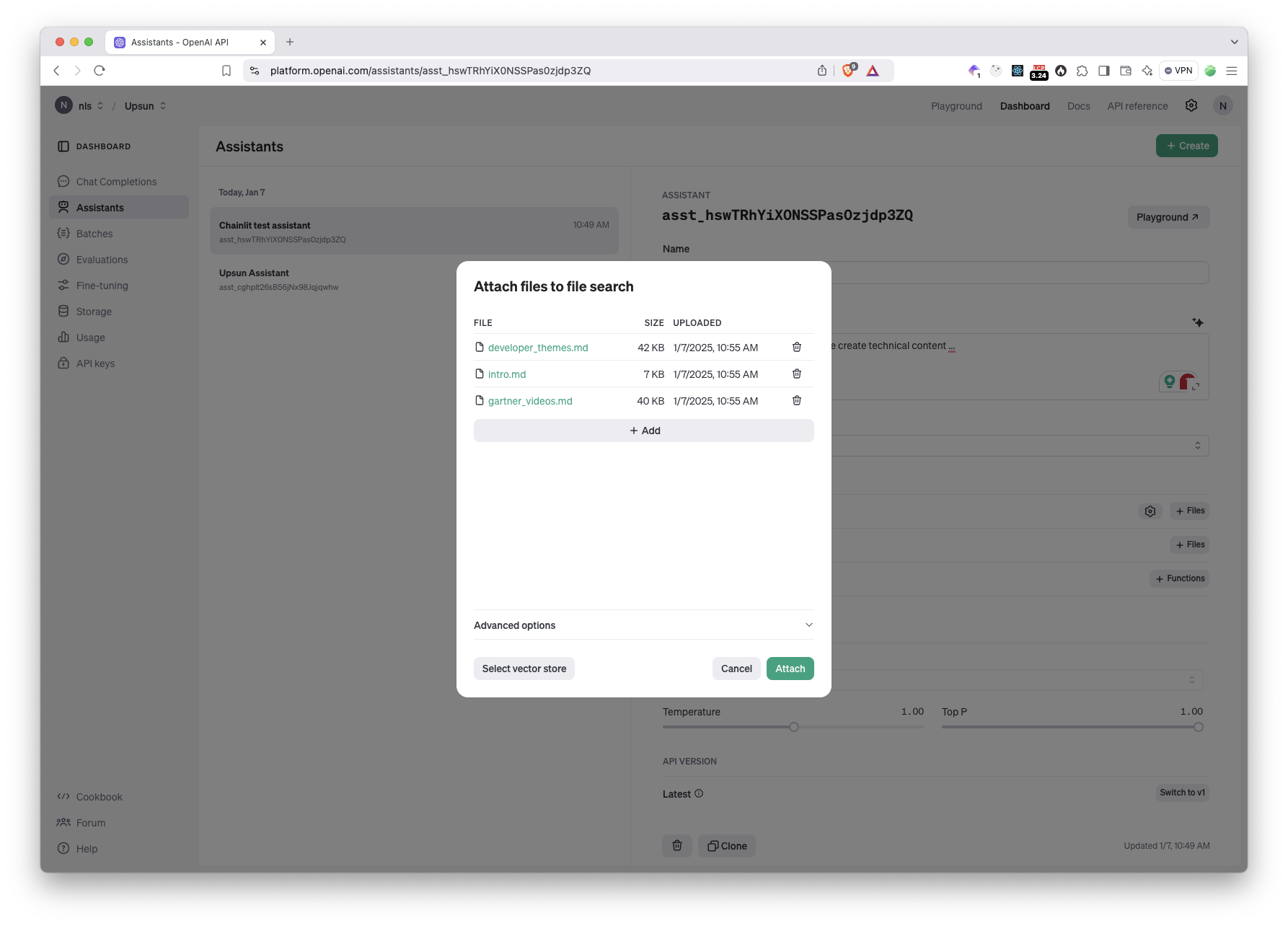
After a few seconds, the content is ingested and transformed into a vector store, ready to be used:
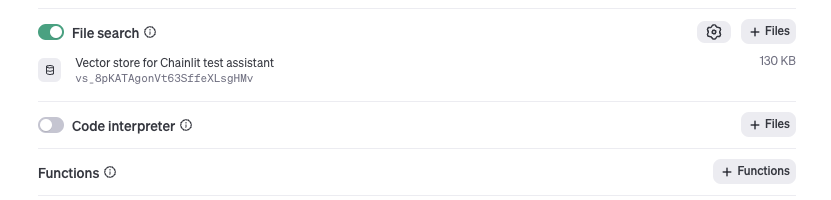
Everything is now ready on the OpenAI side and we can implement the logic in Chainlit.
Adding the assistant logic.
Open app.py and replace the content with the code below:
| |
Feel free to review the whole code but let’s focus on the important parts:
| |
on_chat_start is called when a new chat is created. It creates a new thread on OpenAI to handle the conversation and start it with a new welcome message.
| |
on_message is triggered whenever the user is submitting a new message. It sends the content to the OpenAI API on the thread and then launches a stream. You can find more information on how they work on the official documentation.
To summarize, instead of getting the answer as part of the HTTP response of the Message request, we have to poll the Threads API to find new messages that would have been created. It’s a bit more cumbersone but allows OpenAI to perform multiple operations asynchronously and add the results into the thread.
Commit the changes and deploy
Let’s state and commit the changes:
git add .upsun/config.yaml
git add app.py
git commit -m "OpenAI assistant version"And we can now deploy:
upsun pushTest the Assistant
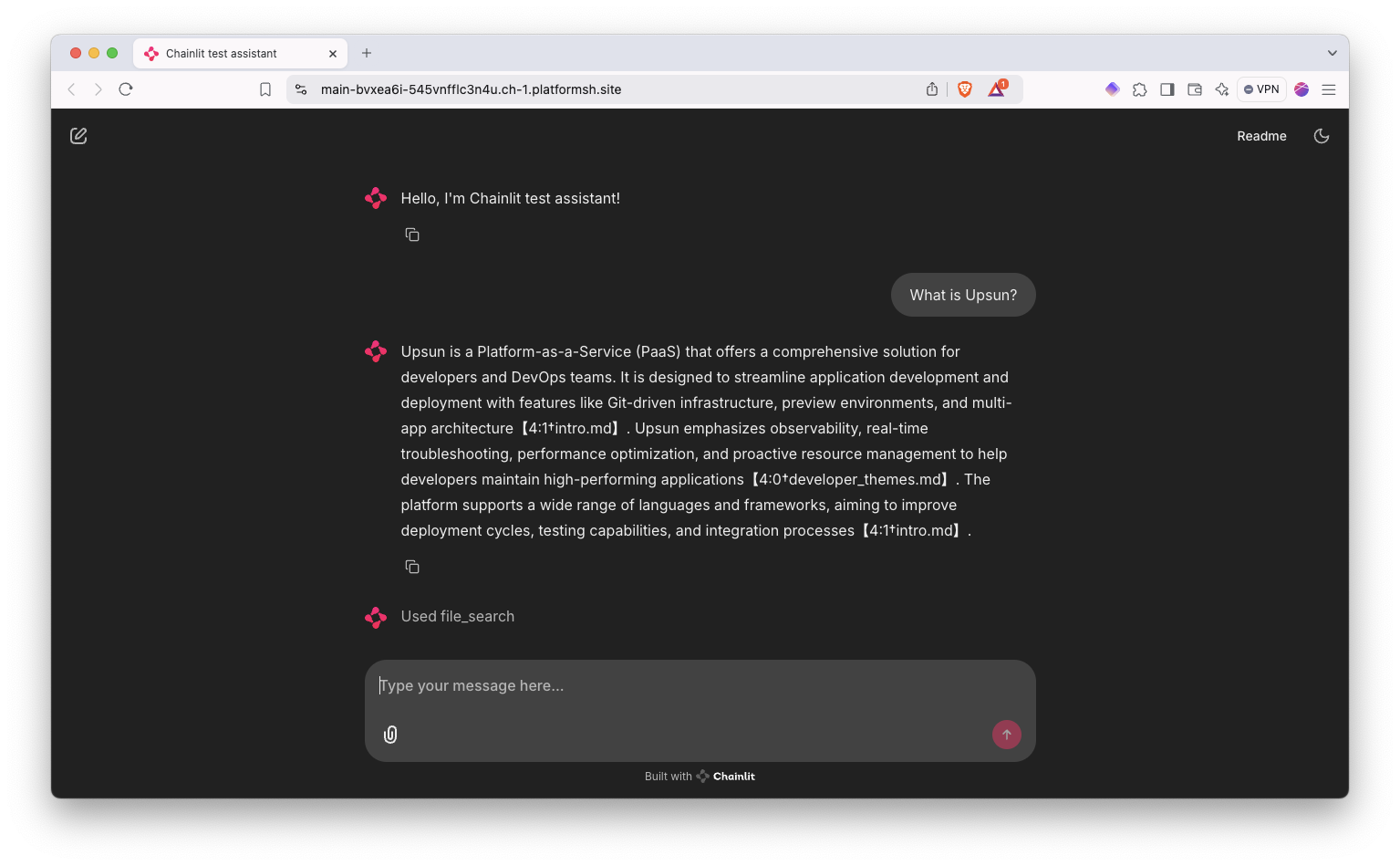
Go to the deployed Chainlit instance and ask any question related to the content you uploaded:
You should get an appropriate answer! It might be a bit slow due to the polling process especially on the first message. But it works! OpenAI gives you the indications where in your documents it sourced some of the information
Second implementation: OpenAI + llama_index
So the goal for this version will be to build the knowledge locally and then rely on OpenAI to output the final form.
Create a new branch
Let’s kickstart this by working on a new environment/branch:
git checkout -b llama-indexAdd two new folders and mounts to store our data
Create the folders first on your machine:
mkdir data
mkdir storageAnd now add the mount to our Upsun configuration:
mounts:
"/data":
source: "storage"
source_path: "data"
"/storage":
source: "storage"
source_path: "storage"data will be used for our source documents and storage will handle the cached VectorStore.
Let’s update our app
We will not be using the OpenAI assistant there so the code will be a lot simpler:
| |
Let’s break down the important parts.
When the application is starting, we use the text-embedding-3-small (line 39) to embed our documents into our VectorStore.
$ chainlit run app.py -w --port 8000
2025-01-07 17:06:59 - Loaded .env file
Loading files: 100%|██████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 17.52file/s]And whenever the user creates a new chat, we define a query_engine (lines 43-44). It will be passed alongside every message and will contain the result from the k-search of our vector store. You can note that we are using a similarity_top_k param to define how many documents should be matched when searching.
Settings.num_output (line 41) so llama does not give me a bigger context window than what OpenAI can take. You can get a lot of context in the query and longer answers by increasing these values but this will obviously consume more tokens and generate higher bills so be mindful!Deploy the new environment
As usual, commit and push!
git add .
git commit -m "Switch to llama_index"
upsun pushUpsun CLI will confirm you want to create a new environment:
$ upsun push
Selected project: Chainlit Devcenter tutorial (545vnfflc3n4u)
Enter the target branch name (default: llama-index):
Create llama-index as an active environment? [Y/n]
Pushing HEAD to the branch llama-index of project Chainlit Devcenter tutorial (545vnfflc3n4u)
It will be created as an active environment.Hit Yes and the new app will be deployed in a new isolated environment.
Push some data
In order to have some documents to work with on the Upsun environment, you can automatically upload your data folder:
$ upsun mount:upload
Enter a number to choose a mount to upload to:
[0] data: storage
[1] database: storage
[2] .files: storage
[3] __pycache__: storage
[4] .chainlit: storage
> 0
Source directory [data]:
Uploading files from data to the remote mount data
Are you sure you want to continue? [Y/n]
building file list ... done
./
developer_themes.md
intro.md
sent 27.83K bytes received 92 bytes 11.17K bytes/sec
total size is 90.92K speedup is 3.26Test llama_index
Once deployed, head over to your environment (llama-index-sukwicq-[project id].[region].platformsh.site) and test a prompt:
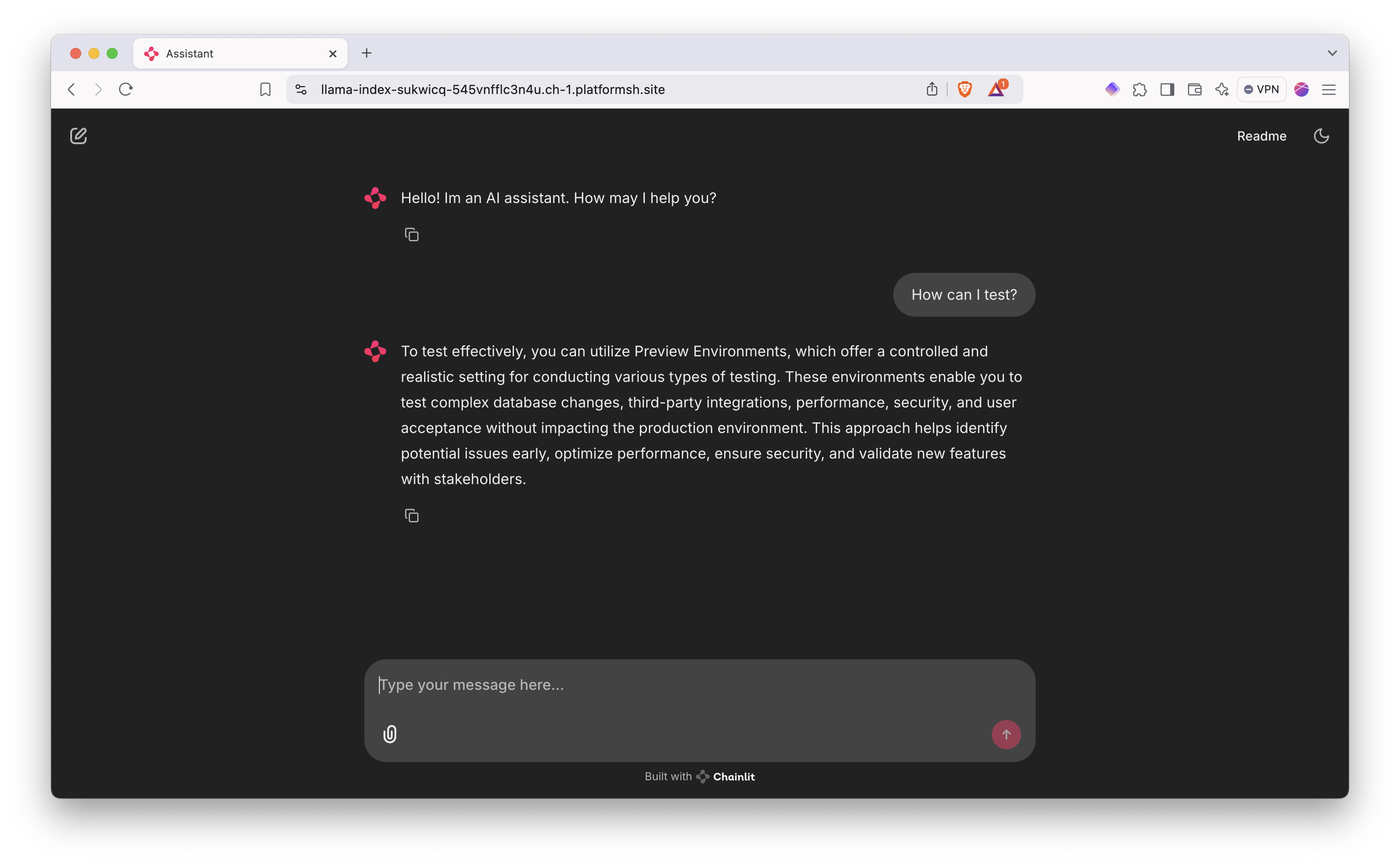
As contrary to the OpenAI file_search, the response does not give you the source of the data as it was passed directly from llama_index to OpenAI.
Bonus: Adding authentification to Chainlit
Now that our Chainlit application is deployed and available, it would be great to add some form of authentication to make sure only you and your folks can access it. While Chainlit has many capabilities for this, we will go for the simpler route of using a sqlite database for this.
Create the database folder
mkdir databaseAnd add the mount in the Upsun configuration:
mounts:
"/database":
source: "storage"
source_path: "database"Add the auth logic to our application
First let’s add a new environment variable:
upsun variable:create env:DB_PATH --value="database/auth.db"We can now add the logic into app.py:
| |
When the script is run, it first check that it can open the database or create it if it doesn’t exist.
Adding @cl.password_auth_callback will automagically add a login form to our app. The logic in auth_callback is pretty simple right there. Feel free to change it the way you want.
We are hashing the form password and looking up for a user that matches both username and password. If so we return the user with the admin privileges.
Create a simple script to generate hashed passwords
import hashlib
import random
import string
def generate_password(length=12):
# Define character sets for password generation
chars = string.ascii_letters + string.digits + string.punctuation
# Generate random password
password = ''.join(random.choice(chars) for _ in range(length))
# Hash the password
hashed_password = hashlib.sha256(password.encode()).hexdigest()
return password, hashed_password
def main():
# Generate password and get its hash
password, hashed_password = generate_password()
# Display both the password and its hash
print(f"Generated Password: {password}")
print(f"Hashed Password: {hashed_password}")
if __name__ == "__main__":
main()You can invoke it and it will output the password and the hash:
$ python create_password.py
Generated Password: F\7r\pQ-jmP$
Hashed Password: 67f4db1ae09453ff6ce68e5d3c138259f80b5b3b6c595226435323d0004d99f7Adding users
Now it’s just a matter of creating new records in the users table of our auth.db. Don’t forget you need to put the hashed version of the password in the database! You can either run queries through the CLI or use GUI:
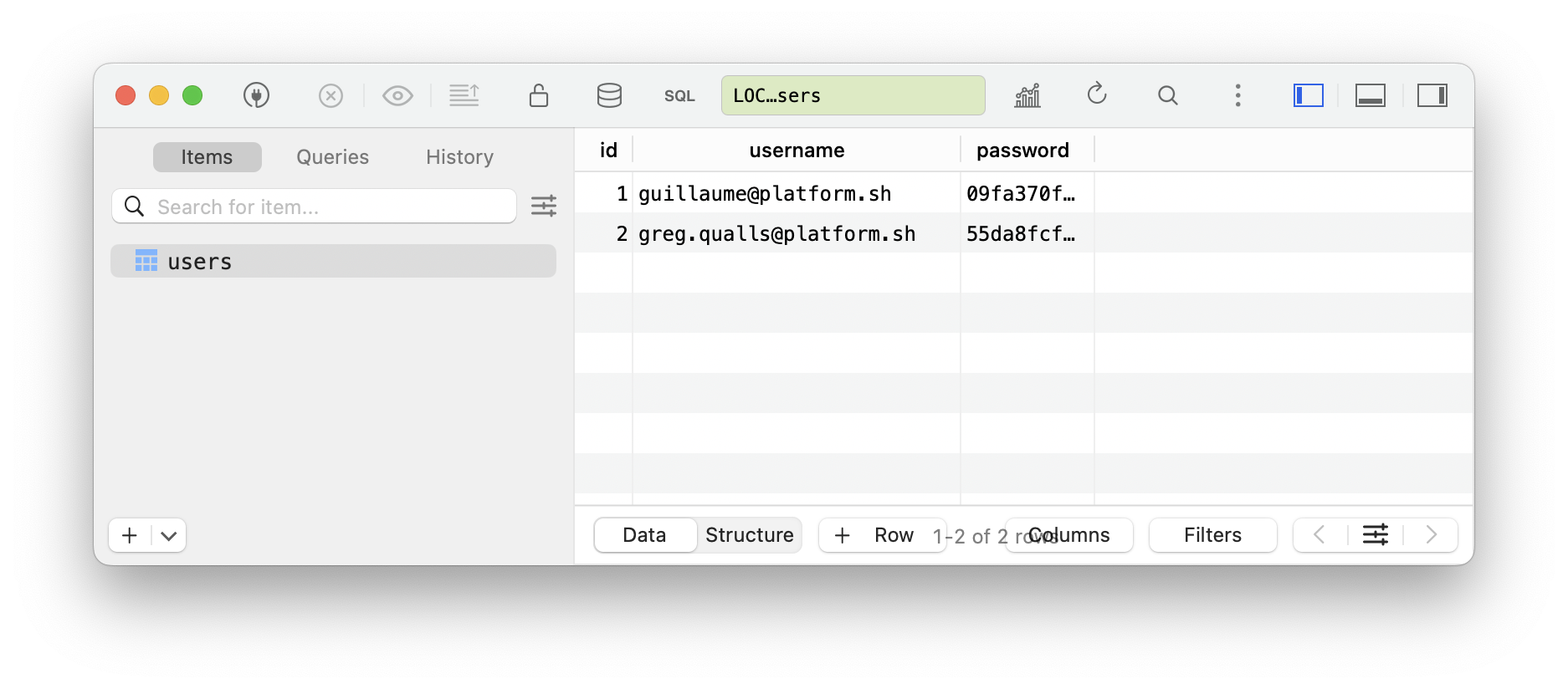
And we should now be ready to go!
Deploy the authentication
As usual, commit and push:
git add .
git commit -m "Add auth"
upsun pushIn order for our authentication to work, let’s upload our sqlite database:
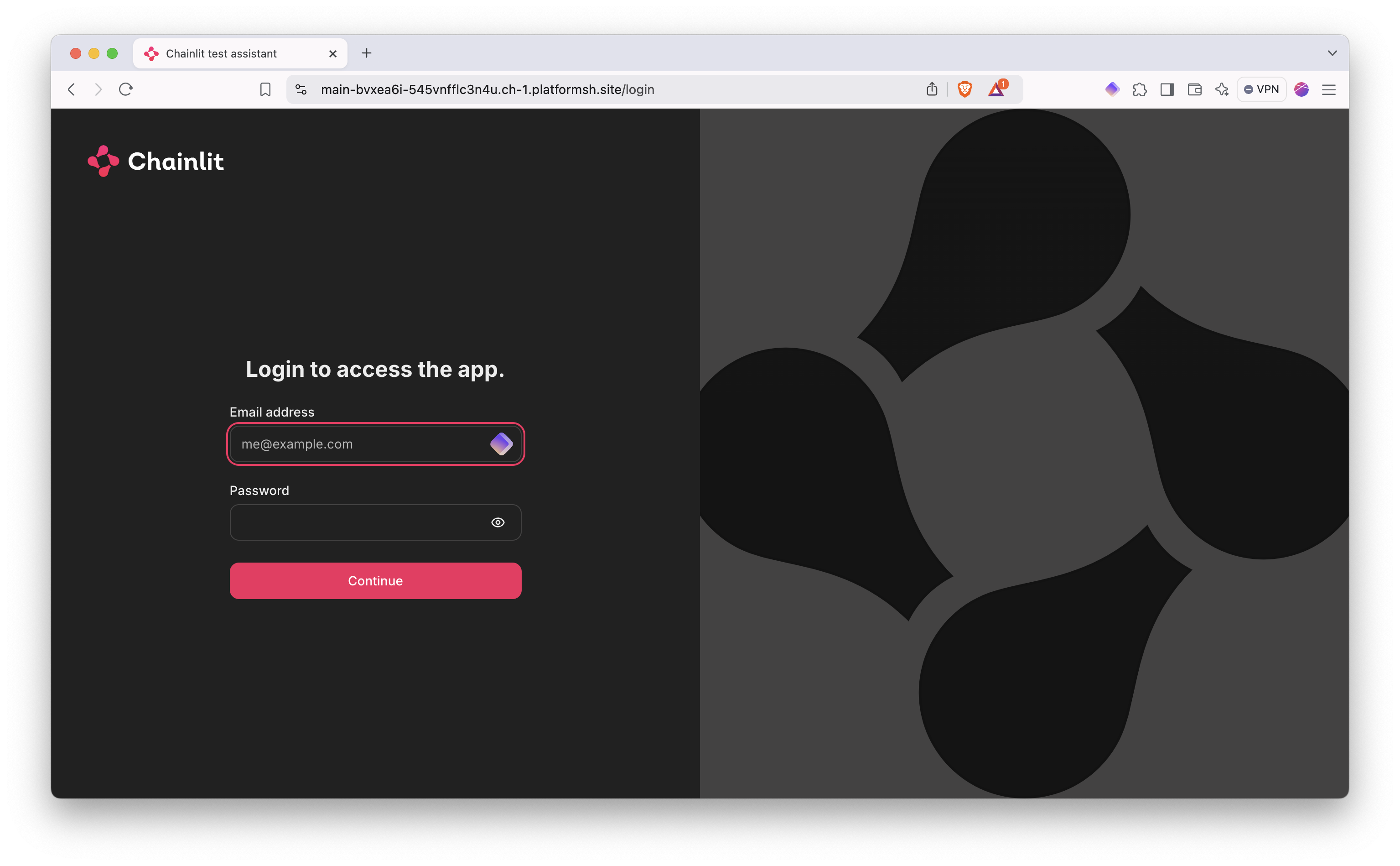
upsun mount:uploadLogin now!
You now need to input your credentials to login to your Chainlit interface:
Conclusion
In this tutorial, we’ve successfully deployed a Chainlit application on Upsun with two different RAG implementations, each offering unique advantages. The OpenAI Assistant approach provides built-in file handling and clear source attribution, while the llama_index implementation offers more control over the embedding process and local vector store management. We’ve also added a layer of security through SQLite-based authentication, making the application production-ready.
By leveraging Upsun’s platform capabilities, particularly its storage mounts and environment management, we’ve created a scalable and secure conversational AI interface that can be adapted for various use cases. Whether you’re building a document-aware chatbot, a knowledge base assistant, or any other RAG-powered application, this setup provides a solid foundation for further development.
Remember that while we used OpenAI’s models for generation in both implementations, the architecture we’ve built could be adapted to work with other language models, including local ones, depending on your specific needs and requirements.