How we cut AWS bandwidth costs 95% with dm-cache: fast local SSD caching for network storage

The bandwidth billing challenge
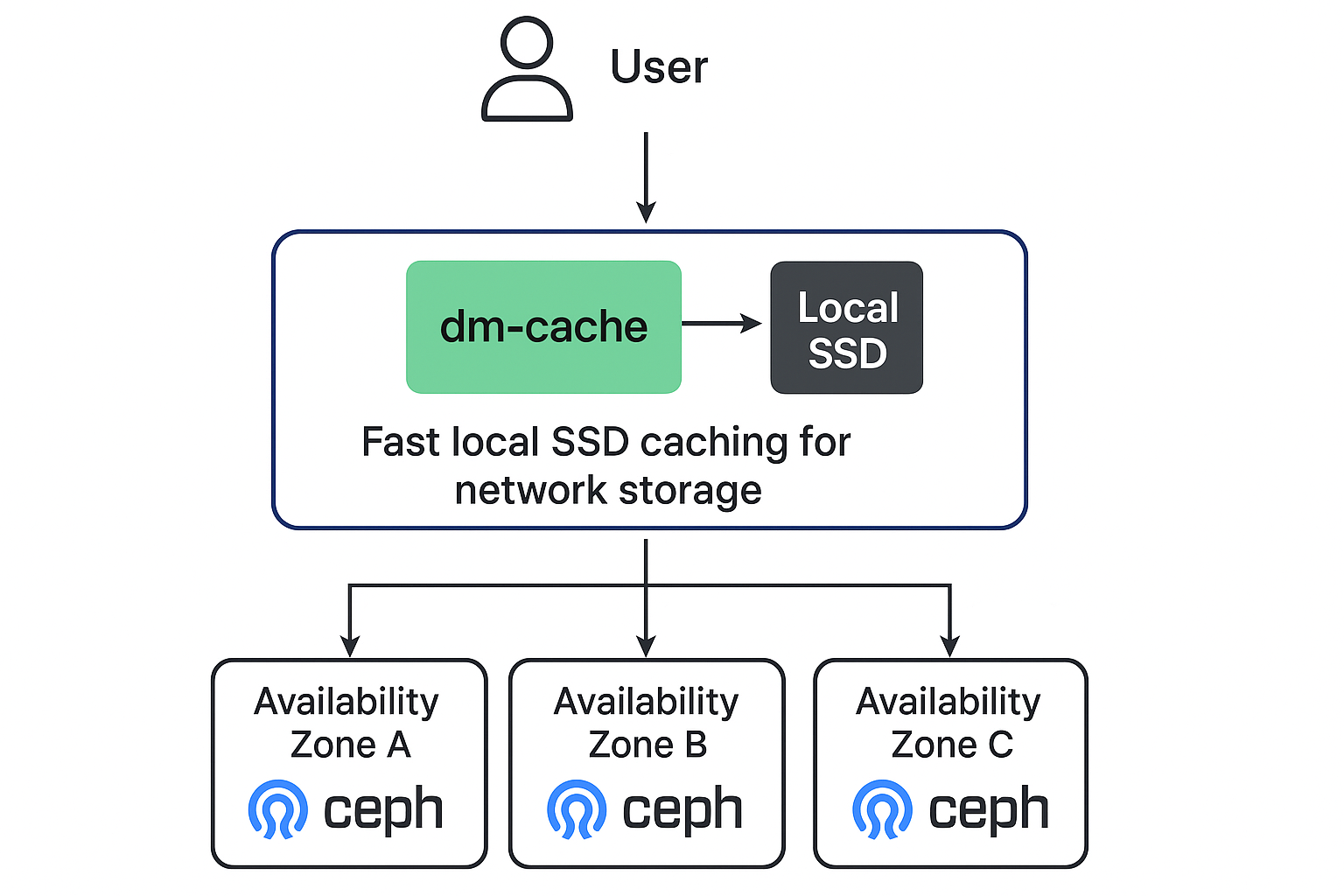
When deploying infrastructure across multiple AWS availability zones (AZs), bandwidth costs can become a significant operational expense. Some of our Upsun infrastructure spans three AZs for high availability, but this architecture created an unexpected challenge with our Ceph-based storage system.
Since Ceph distributes data across the cluster and AWS bills for inter-AZ traffic, approximately two-thirds of our disk I/O traffic crossed AZ boundaries—generating substantial bandwidth charges. With all disk operations flowing over the network rather than accessing local storage, we needed a solution that could reduce this costly network traffic without compromising our distributed storage benefits.
The local SSD caching experiment
Our AWS instance types included small amounts of local SSD storage that weren’t being utilized for primary storage. This presented an opportunity: what if we could use these fast, local disks as a read cache in front of our network-based Ceph storage?
We implemented a three-step caching strategy using Linux device mapper (dm-cache):
- Volume partitioning: Used LVM to split the local SSD into small 512MB cache volumes
- Read-only caching: Configured dm-cache to place these volumes in front of our Ceph RBD (RADOS Block Device) volumes, caching reads while passing writes directly through to the network storage
- Container integration: Exposed the dm-cache devices to our containers as their primary storage interface
Understanding dm-cache architecture
The dm-cache kernel module was originally designed to address a classic storage trade-off: placing small, expensive SSDs in front of large, affordable HDDs to create hybrid storage with both capacity and performance. Our use case follows the same pattern—except instead of slow HDDs, we’re caching in front of network-attached storage.
This approach works because of how application I/O patterns typically behave. Most applications exhibit temporal locality in their data access, repeatedly reading the same files or database pages. By caching frequently accessed blocks locally, we can serve repeated reads from fast SSD without network round-trips.
For detailed setup instructions, check out the Red Hat documentation on caching logical volumes.
Implementation considerations
When implementing dm-cache in production environments, consider these key factors:
Cache sizing: While our 512MB cache proved effective, the optimal size depends on your application’s working set. Monitor cache hit rates and adjust accordingly.
Write policy: We chose write-through mode exclusively, where all writes bypass the cache and go directly to network storage. This decision was crucial for Upsun because we host thousands of e-commerce applications where data integrity is non-negotiable.
In e-commerce environments, every transaction—whether it’s inventory updates, order processing, or payment confirmations—must be immediately persisted to durable storage. A lost write due to cache failure could mean:
- Customer orders disappearing after payment processing
- Inventory miscounts leading to overselling
- Financial transaction data corruption
- Regulatory compliance violations
While write-back mode offers better write performance by buffering writes in the local cache, it introduces risk scenarios we couldn’t accept:
- Cache device failure: Unwritten data in the cache would be permanently lost
- Power failures: Cached writes might not survive unexpected shutdowns
- Split-brain scenarios: Cache and storage could become inconsistent during network partitions
For e-commerce workloads, the performance benefit of write-back mode isn’t worth the data integrity risk. Our customers depend on transactional consistency, and write-through mode ensures every write operation is safely committed to our replicated Ceph storage before the application considers it complete.
Performance monitoring: Track metrics like cache hit ratios, network bandwidth utilization, and application response times to validate the effectiveness of your caching strategy.
Results: dramatic performance and cost improvements
The impact exceeded our expectations. With cache volumes of only 512MB serving RBD volumes ranging from 5-50GB, we achieved:
- 95% reduction in read traffic over the network
- 30x improvement in IOPS for cached operations
- 50% reduction in read latency
- 30x increase in read bandwidth for frequently accessed data
These improvements translate directly to cost savings through reduced inter-AZ bandwidth charges, while the performance gains provide a significantly better experience for applications running on our platform.
Why this approach works at scale
The success of this caching strategy relies on several key factors that align well with typical container workloads:
Read-heavy patterns: Many applications read configuration files, static assets, and database indexes repeatedly, making them ideal for caching.
Working set locality: Applications tend to access a subset of their total data frequently, allowing small caches to be highly effective.
Write-through simplicity: By passing writes directly to network storage, we maintain data consistency while avoiding complex cache invalidation scenarios.
The 512MB cache size might seem small, but it’s sufficient to cache the most frequently accessed blocks for typical containerized applications, delivering outsized performance benefits.